Depth estimation plays a big role in robotics, autonomous driving (mapping, localization and obstacle avoidance), augmented reality and many other computer vision technologies across many industries. It is an important phenomenon which helps in understanding and in virtual reconstruction of 3D real world representation by measuring the distance of the scene in the 3D world to a viewpoint. Traditional methodologies often made use of depth sensors such as LIDAR (Light detection and ranging) and RGB-D cameras. LIDAR uses a laser to get the depth map and RGB-D cameras produce “pixel-level” depth estimation directly by making use of an infrared (IR) camera and IR laser emitter. These methodologies, though effective to some extent, have proven to be very expensive and inhabit some limitations including, having limited range of measurement, large physical build and extensive power consumption. These limitations opened doors for research on acquiring depth from images. This blog post is aimed to give a concise overview of a thesis study that was conducted to research the idea of implementing a depth estimation system that can be deployed on a physical robot and work in real time.
So what is depth? And what is depth estimation?

Depth, in simple terms, means the distance of a point in a 3D world from the point of vision. In the figure above, the left image represents an RGB image of a scene and the right image is the respective depth image of the scene. Depth estimation is the task of estimating depth of each pixel in an RGB image and obtaining a 2D depth map of the scene.
The traditional methodologies used for depth estimation, as mentioned above, include the use of LIDAR and RGB-D cameras. The limitations that come with these tools, led to the discovery and popular use of images for the task of depth estimation. Images are the primary visual representation of the world that we see. In an image, each pixel depicts a numerical value that corresponds to a feature in the 3D world. In the course of human scientific advancement, image data has been crucial. Extraction and investigation of image data has proven to have deep impact in various applications: Medical imaging, autonomous vehicles, traffic flow analysis, and machine inspection across multi-platform industries.
Binocular depth estimation and Monocular depth estimation
Binocular depth estimation requires left and right images taken from two cameras that are fixed to make depth estimation of a particular scene. On another note, monocular depth estimation produces pixel-level depth estimation of a scene from a single, 2D RGB image representation of it. These approaches produced promising methodologies to address the limitations posed by the traditional tools mentioned above. Deep learning based monocular depth estimation methodologies train deep neural networks with sophisticated architecture on RGB-depth image datasets like NYU depth v2 and KITTI. RGB–depth datasets like the ones just mentioned are not abundantly available. Hence, it is safe to say that there is the need for collection of additional RGB – depth datasets. Accordingly, one of the main goals of the thesis study was to collect data from a simulation environment and train a depth estimation neural network model with that data. The model was then evaluated on real world data.
Goals of the study
- Train a depth estimation neural network to make depth estimation on video sequences. The idea behind this was to exploit the temporal information that is embedded across consecutive frames in a video sequence on top of the spatial information of individual frames.
- Collect simulation data from NVIDIA-Isaac Sim simulation environment for training of the model and collecting data from a real world robot for the evaluation of the model.
Data Collection
NVIDIA-Isaac Sim simulation environment data collection
NVIDIA Isaac Sim is a simulation software, developed by NVIDIA, which is mainly used in robotics. It provides tools and applications to simulate robots in a virtual world, train them, test them and also facilitates data collection through Synthetic Data Generation tool. For this thesis, we gathered data from 4 environments in NVIDIA Isaac Sim. Two of the environments were a variation of a built in Office simulation environment and the other two were a variation of a built in Warehouse simulation environment. The figure below depicts some of the scenes from these environments and their corresponding depth images.

Data Collection in Karelics Office


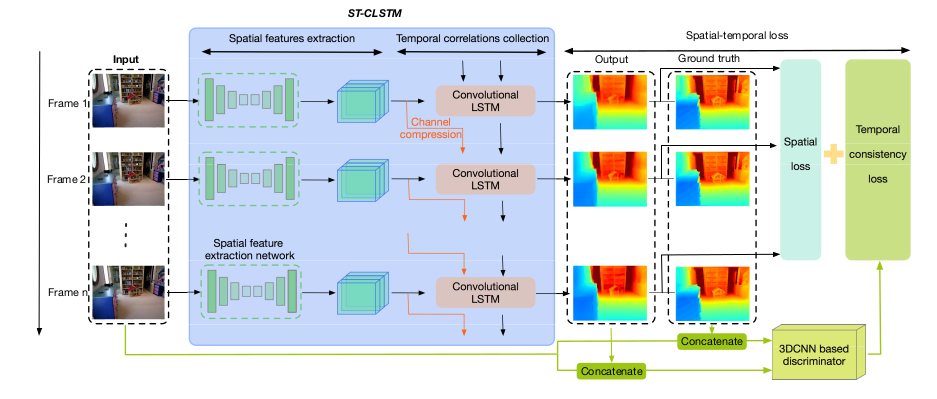
Neural network architecture
Results
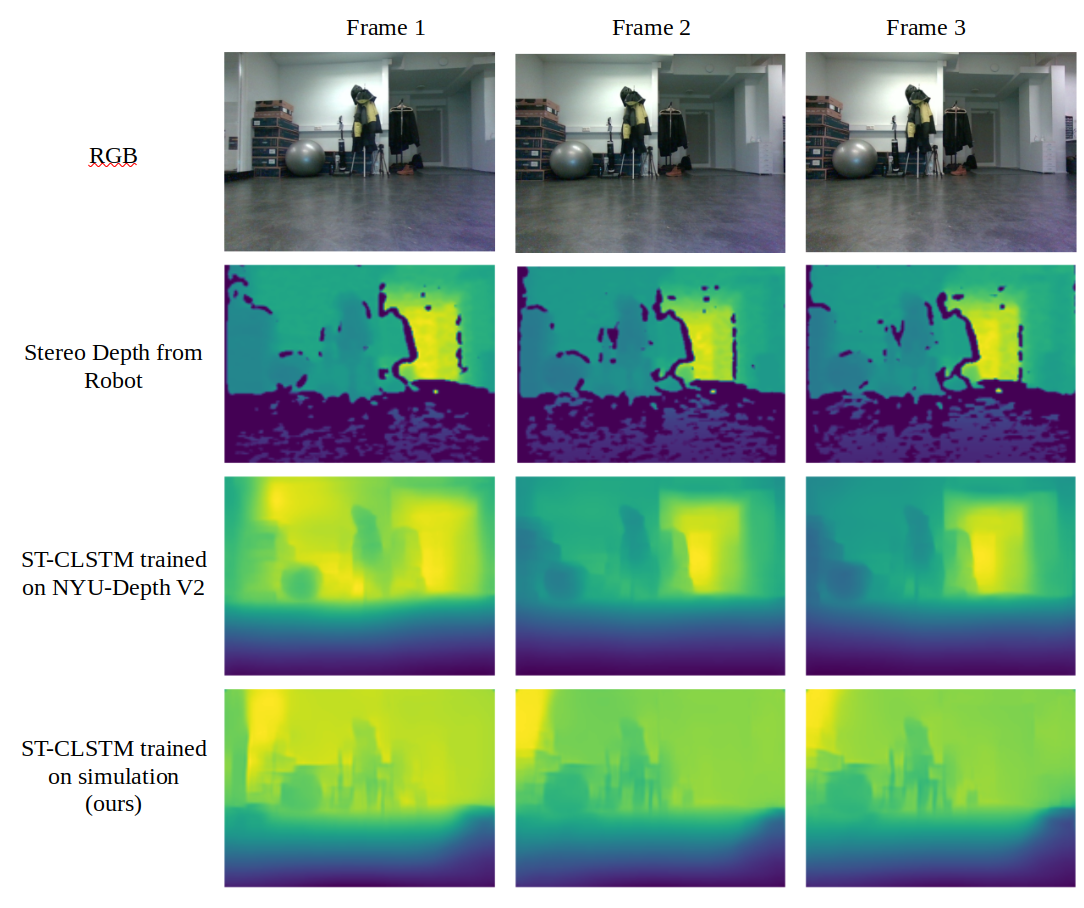
Figure depicted below shows some of the frames from a video collected from URobot Antero in Karelics office, depth estimated from the integrated cameras in the robot and the estimation results from the neural network model trained in two different scenarios: real world data trained and simulation data trained. We can observe from these results that the model we trained in the simulation environment produces decent results as compared to the model trained on the real world data. What makes this more fascinating is the fact that the data we collected from the simulation environment was significantly smaller in size (10K frames from 4 scenes) when compared to the real world dataset (120K frames from 249 scene) that was also used to train the model to observe the comparability of the model performance in both training scenarios.